Image-to-video (I2V) generation has made rapid progress, yet scaling to high resolution (e.g., 2K) is bottlenecked by the efficiency–fidelity dilemma: end-to-end high-resolution generators deliver strong quality but require tens of thousands of GPU-seconds per clip, while low-resolution generation followed by video super-resolution (VSR) loses the input-image condition and hallucinates details inconsistent with the reference.
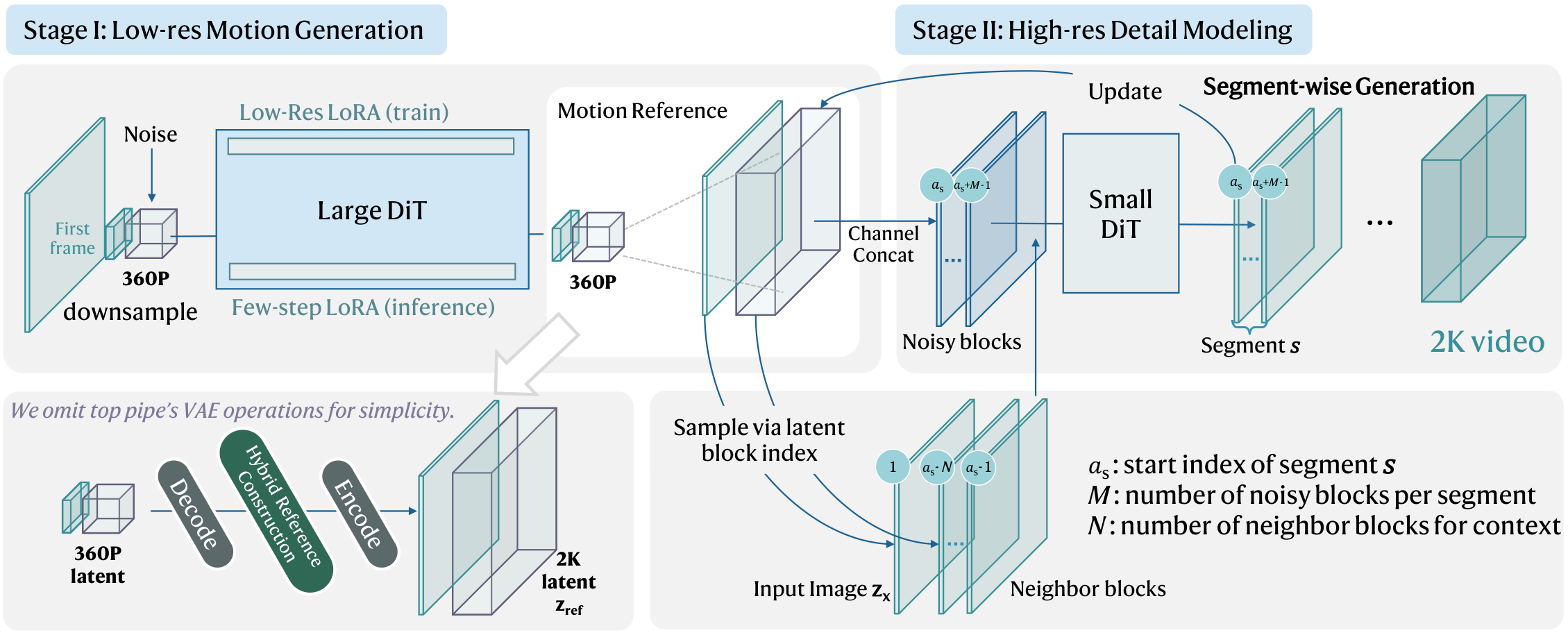
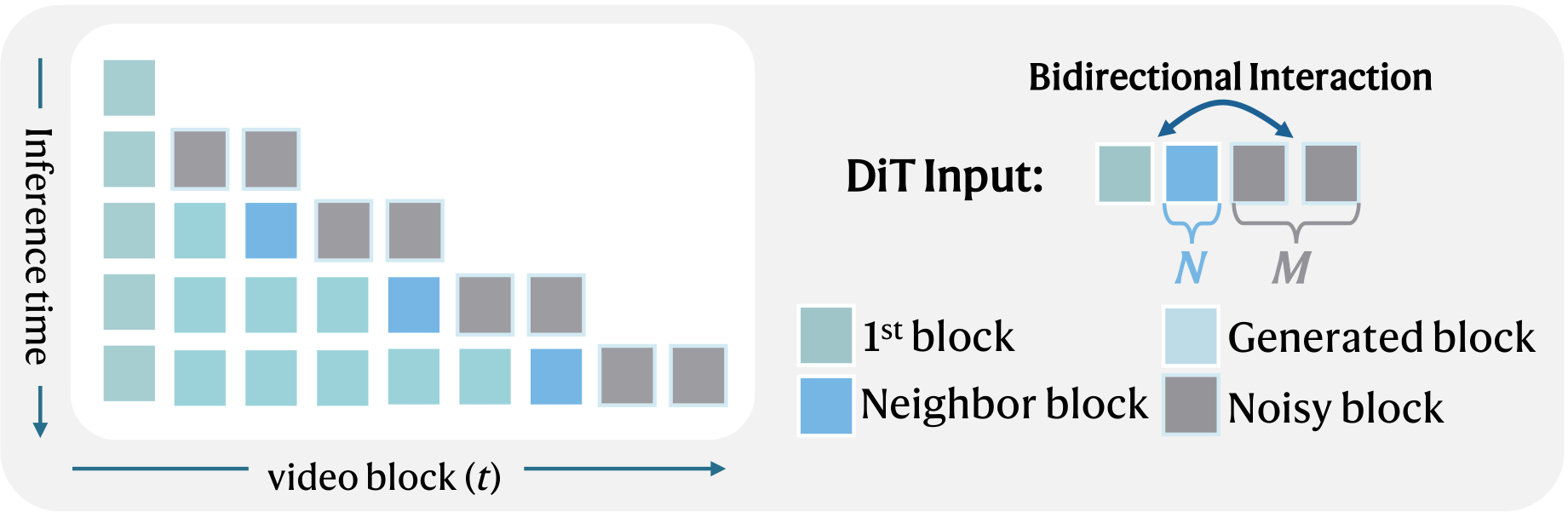
We present SwiftI2V, an efficient two-stage framework that resolves this dilemma. Stage I produces a low-resolution motion reference with a large backbone under few-step sampling; Stage II refines it to 2K by taking both the input image and the Stage I output as strong conditions. To handle long-duration 2K refinement within limited GPU memory, we introduce Conditional Segment-wise Generation (CSG) with bidirectional contextual interaction, which divides the temporal axis into bounded segments augmented by neighboring contexts — mitigating error accumulation while retaining high-frequency fidelity. A stage-transition training strategy further closes the train–test gap by simulating Stage I style artifacts during Stage II training.
On VBench-I2V at 2K, SwiftI2V matches strong end-to-end baselines on key I2V metrics while reducing total GPU-time by 202×. Notably, it enables practical 2K I2V generation on a single consumer RTX 4090 within 24 GB of memory.